Drink Recipe: Unicorn Elixir
Unicorn Elixir by Austin Burk

Ingredients:
- 1.5 oz vodka
- 1 oz triplesec
- 1 oz grenadine
- 1 oz cream of coconut
- 2 oz pineapple juice
- 1 oz lemon juice
- Edible glitter (optional)
- Rainbow sprinkles (optional)
How to prepare:
If using sprinkles: rim a tall glass with a thin layer of frosting or corn syrup and then dip the rim into rainbow sprinkles.
In a cocktail shaker, combine vodka, triplesec, grenadine, cream of coconut, pineapple juice, and lemon juice. Add a handful of ice.
Then, shake well until all ingredients are well combined.
Strain the cocktail into the rimmed glass.
If you've got edible glitter, stir it into the cocktail now.
Drink Recipe: The Michigan Cherry Mule
My (Austin Burk) recipe.

Takes me back to trips to the Upper Peninsula.
Note that this contains ginger ale rather than ginger beer.
The Michigan Cherry Mule
Ingredients:
- 2.5 oz of Michigan cherry infused vodka (Increase by 0.5 oz to amplify cherry flavor)
- 0.5 oz of cucumber vodka
- 0.5 oz of fresh lime juice
- 4 oz of Vernors ginger ale
- Splash of cherry juice (optional, adds extra cherry flavor)
- Garnish: Lime wheel and fresh, Michigan cherries
Instructions:
1. Fill a mule mug or highball glass with ice.
2. Pour in the Michigan cherry-infused vodka and fresh lime juice.
3. If using, add a splash of cherry juice.
4. Top with Venors ginger ale, filling the glass.
5. Stir gently to combine.
6. Garnish with a lime wheel and fresh Michigan cherries, on a kebab.
I first tried this, an earlier revision of it, at REO Pub in Lansing, MI — Vanessa mixed it for me to try out :)
Hatena Intern 2023 challenge solution
I solved the remote internship puzzle.
I took a simple brute-force approach.
async function main() {
let result;
for(let i = 0; i < 10000; i++) {
let code = i.toString().padStart(4, "0");
try {
result = await unlock(code);
console.log(`Found code: ${code}`);
return result;
} catch (error) {
// continue...
}
}
throw new Error("No valid code found");
}
main().catch(e => console.error(e));
The solution was...
8107
(If I lived in Japan, I would apply.)
Michigan State University mass shooting: my experience
I found out when someone I knew pinged me in Discord, asking if I was okay.

I was confused at first about what he meant. I had planned to head out to campus that evening, but got diverted due to an issue with my Asterisk PBX. *1
My buddy linked me to an article (I've included a link to an archived version; the live URL has since been updated with updates from the next day.)
"Two dead, multiple wounded." he said.
I was shocked. I have friends at MSU, I go there often and my dad even works there. I switched to another Discord server that I was in, one for Spartans. Chat was moving a mile a minute. One of my friends lived on campus, so I texted to see if she was okay -- I didn't get a quick response, so I then called my dad to see if he was alright.
"I saw the email," he said, referring to a mass mailing sent out by MSU Public Safety. "I went home a few hours ago, so I'm alright."
In the Spartan Discord server, hundreds of people were talking, some listening to an internet feed of a police scanner; others were asking about where to go, and trying to eke out any usable information from the flying rumors and confused analyses. "Barricade your dorm room door," one person said, "then turn off the lights and keep quiet."
My friend still hadn't gotten back to me. By now, I'd found the police scanner and was mentally trying to match up what I was hearing with ideas of where she could be -- I had heard rumors of one of those killed being a girl. I sent her another message. A few minutes later, she finally got back to me. "I'm okay, I'm safe." Phew. We talked very briefly. "This is crazy," she said. "My roommate and I put a dresser in front of the door."
"Are you listening to the scanner?"
"I'm not, but it's quiet where we're at."
The evening dragged on, peppered with the occasional contact from friends who were checking on me, and some chatting with friends and family. One of the things that was unclear for most of the evening was the scope of the attack. The scanner traffic was mixed between people coordinating evacuations of students to safe locations, as well as reports of people with guns, bombs, across campus. I later figured out that what I was hearing was the emergency dispatcher sending people to check on reports that had been called in.
Around midnight, clearer details had come through. The suspect had left campus and gone closer towards the greater Lansing area, and having been confronted by police, turned his gun on himself. At some point I found out that the location of some of the shooting had been the Union building -- the same place I'd planned on going to before going home to troubleshoot my PBX.
Whoa. Lucky, maybe. Blessed, more likely.
Since then, I've been trying to cope with what happened. It's been a bit over a day now. Even though I'm not a student, MSU has been for years a place for me to walk, relax, think, and occasionally socialize. Sometimes I enjoyed taking evening walks next to the Red Cedar River, or visiting the dairy store, or just taking a seat by the river and whistling a tune. I'm not sure how I feel about any of that anymore.
I'm hoping to meet up with my friend at some point this week.
Tuesday morning, I visited the Sparty statue on campus. I left a few flowers.


I'm not really sure where to go from here.
*1:Maybe God's the one that broke my inbound Callcentric numbers. All it took was a `systemctl restart asterisk` to fix it. Nothing else seemed to be out of place, and I can't find any logs about what happened. Thanks be to God.
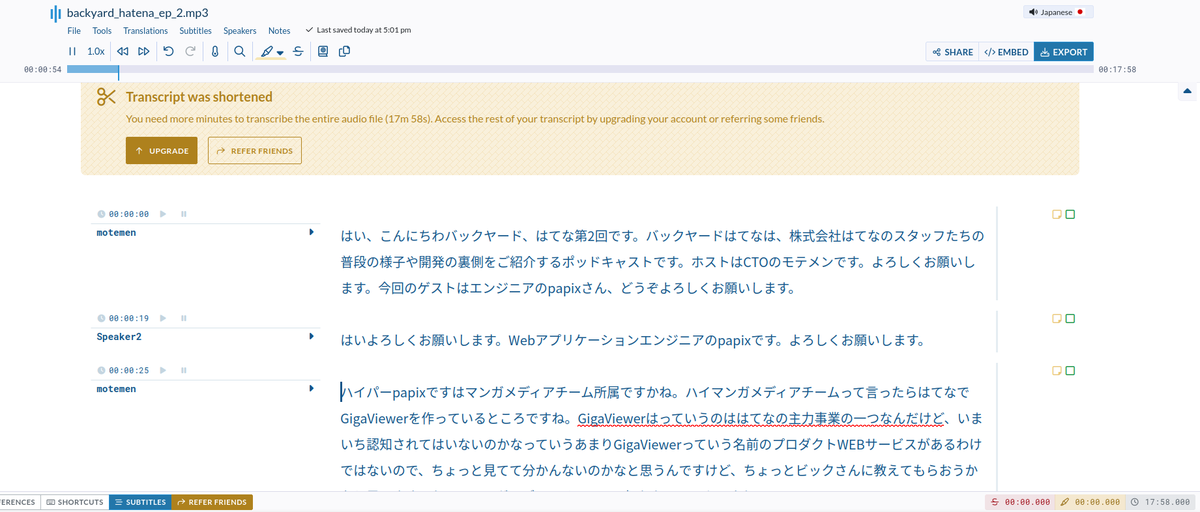
Another thing on the pile: Backyard Hatena podcast archive/transcriptions
I decided that I'd try to archive the Backyard Hatena podcast and get transcriptions made up for it. I've only got one transcription "done" and that was with something called Sonix, which seems capable, but also rather expensive considering that I have a budget of roughly zero at present.
Who knows, maybe I can convince them to give me a discount or something haha. I'll figure something out because I really want to know what goes on in the back catalogue of episodes/any new ones that come out.
See these entries for other Hatena-related things that I've been working on archiving:
If anyone wants to help with fixing the transcription(s), feel free to submit a PR. I'd prefer to have the initial run done by machine for sake of consistency, and revisions done by human after that.
Introducing my Hatena Investor Relations Media Archive
I'm starting to run out of "easy" Hatena-related things to archive, so I've started digging into more things that I feel I haven't put enough focus on. While I'm struggling to understand the actual content of these meetings, I've started to archive Hatena's IR documents and media. I'm hoping to get these machine-captioned so that I can review them, as well as have the PDFs properly OCR'd so that I can translate them.
Hatena Investor Relations Media archive
Anyway, there it is -- At some point I'll try to add some automation so that I don't have to manually keep it up to date.
All the video assets are stored in Git LFS, similiar to what I do for hatena-app-archive.
I'm doing something a bit different here in that I've downloaded HTML from slide decks as well to try to preserve the historical context of presentations. (But I haven't rewritten it for offline viewing or anything).
At some point I'll do more with it, but I just wanted to make sure I had that base covered.
Motivation
My motivation here that there's large parts of Hatena's business that I don't really have an adequate understanding of. I have a fairly comprehensive knowledge of some parts, but it's very lacking in other parts, especially where the documentation is in kanji-heavy Japanese in places where I can't easily use machine translation (PDFs, the Backyard Hatena podcast, etc)
Additionally, Hatena's stock (TYO: 3930) seems to have hit a record low of 1000 JPY today. I want to better understand why, and to gain that understanding, I need to vastly improve my understanding of the company's financials.
I still dream that one day I'll be able to work for Hatena, but unfortunately, that door still seems to be closed to me due to my location and my inadequate understanding of the Japanese language. (I am still practicing daily, but my motivation suffers from having no real pressing reason to do so.)
Introducing my Hatena Zendesk archive(r)
Today I made another one of my Hatena-related projects publicly accessible. Believe me, I have a lot more of these things.
Essentially, it should automatically archive articles from all of Hatena's Zendesk help centers.
It's in a mostly finished state, but I might add a few more things to it for completeness sake, like downloading of article attachments (which I was already doing separately)
I don't think it will be very useful to anyone when you can just visit the help centers yourself. I'm more interested in knowing when article content changes. Maybe it will be useful to other people who want to archive a Zendesk Help Center.
See also, an archive of Android apps created by Hatena: